IBM Snap Machine Learning
IBM Snap ML Distributed High Performance Machine Learning Library
IBM has developed an efficient, scalable machine learning library that enables very fast training of generalized linear models. Using this library, clients can remove training time as the bottleneck for machine learning workloads, paving the way to a range of new applications.
This library, called Snap Machine Learning (Snap ML), combines recent advances in machine learning systems and algorithms, to accelerate the most popular machine learning algorithms using GPUs. This was made possible by algorithmic innovations, but also by the use of the high-speed interconnection link between GPUs and Power9 CPUs, the Nvidia NVLink 2.0.
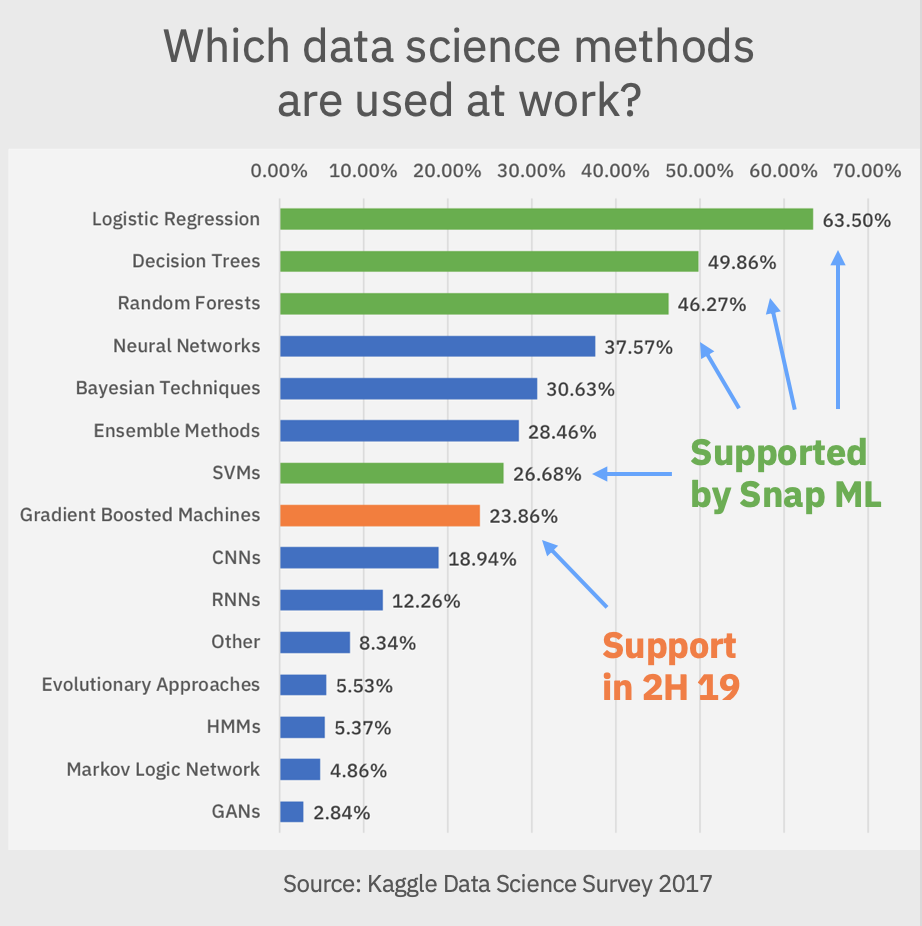
The importance of this state-of-the-art library hinges to the fact that logistic regression is by far the most used method at work by data scientists today, followed by decision trees and random forests and all of them, including Support Vector Machines (SVMs) are supported by Snap ML, so this is a great opportunity to position IBM as the leader in Machine Learning Worldwide.
Snap ML is offered through PowerAI (current version 1.6.0, released March 22nd), where it exposes two APIs, a Python one for single-machine use or distributed use across a cluster, and a Spark one for use in an Apache Spark cluster.
Snap ML (PowerAI 1.6.0) currently supports:
- Generalized Linear models
- Logistic Regression
- Linear Regression
- Ridge Regression
- Lasso Regression
- Support Vector Machines
- Tree-based models
- Decision Trees
- Random Forest
- 2H19 release will add support for Gradient Boosting Machines (GBMs)
Snap ML Now 4X Faster than Scikit-Learn
Snap ML’s implementation of random forest is 2-4X faster than sklearn and decision trees 3-4X faster than sklearn and supports Generalized Linear Models and Tree-based models. Sklearn is the most widely-used Machine Learning framework based on the Kaggle Data Science Survey 2018.
Discover Snap ML's Unique Value Proposition
Distributed Training
IBM has built the system as a data-parallel framework, enabling clients to scale out and train on massive datasets that exceed the memory capacity of a single machine, which is crucial for large-scale applications.
GPU Acceleration
IBM has implemented specialized solvers designed to leverage the massively parallel architecture of GPUs while respecting the data locality in GPU memory to avoid large data transfer overheads. To make this approach scalable, IBM takes advantage of recent developments in heterogeneous learning in order to achieve GPU acceleration even if only a small fraction of the data can indeed be stored in the accelerator memory.
Sparse Data Structures
Many machine learning datasets are sparse. Therefore, Snap ML employs new optimizations for the algorithms used in the system when applied to sparse data structures.
All of this results in significantly reduced training times and higher levels of accuracy. Unleash all the potential of Snap ML on an IBM POWER9 Systems.
Read the Latest Snap ML Blog Post
Sumit Gupta talks about the advances of Snap ML, a python-based machine learning framework that is designed to be a high-performance machine learning software framework.
READ THE BLOG POSTGet Started with Power AI and Snap ML
Why wait? Experience Power AI with Snap ML for your machine learning applications on Cirrascale's revolutionary dedicated, multi-GPU cloud platform.
SIGN UPStart Now with a 7-Day FREE TRIAL of PowerAI and Snap ML with Cirrascale
IBM and Cirrascale Cloud Services have partnered together to enable customers across all industries to harness the full potential of AI in their businesses. With IBM PowerAI and SnapML, data scientists and subject matter experts can scale out and train on massive datasets that exceed the memory capacity of a single machine, which is crucial for large-scale applications.
If you would like to see if you qualify for this free 7-day trial to test PowerAI and Snap ML on IBM Power, complete the form to the right and we'll touch base with you within 48 hours to schedule you for your test drive. Systems are limited, so it is first come, first served, but we'll do everything we can to help you get started quickly.
